最近,网友ywzhaiqi/Liu Binyan等开发了一个豆瓣图书、电影搜索下载的脚本:Douban Download Search。其主要功能就是集中各种图书、电影等搜索工具和网站,方便查找相应的资源链接,颇为方便。
前几天,看了一下,刚开始弄了小半天不知道怎么安装。后来,第二天才找到安装教程,原来,这个脚本需要先安装Tampermonkey等脚本管理器,然后再将代码复制过去。
安装好后,简单看了一下,发现收录的网站主要是针对普通用户,缺失一些个性化的网站,比如古籍和外文书类,于是我就想着如何去打造一个个性化的脚本。(假装)仔细阅读了一下脚本源代码,尽管自己对代码一窍不通,但是还是看出了一些门道,感觉自己可以依葫芦画瓢,添加几个网站。
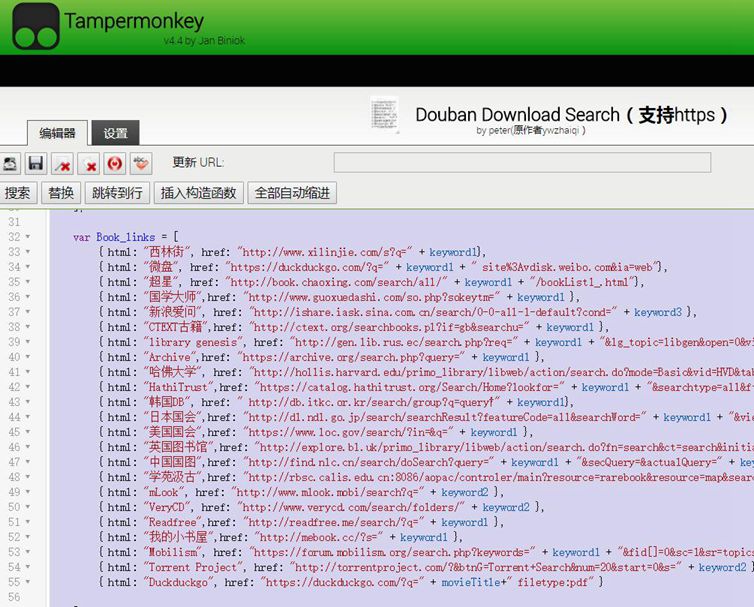
比如源代码:
{ html: “百度盘”, href: “http://pansou.com/?q=” + keyword1},
{ html: “Library Genesis”, href: “http://gen.lib.rus.ec/search.php?req=” + keyword1 + “&lg_topic=libgen&open=0&view=simple&res=25&phrase=1&column=def”},
最关键的部分就是检索引擎地址,主要由主网址+检索命令代码+关键词三部分构成,最简单的就是百度盘的地址,稍复杂的是Library Genesis,需要自己根据检索网址来寻找规律。(当然,有些网站可能有直接的公开API或说明书,但我没找到。)
经过多次尝试,总算成功添加了Internet Archive/美国、英国、日本国会图书馆/韩国DB/HathiTrust/哈佛大学图书馆/中国哲学电子书等多家常用网站的代码,如下:
{ html: “西林街搜索”, href: “http://www.xilinjie.com/s?q=” + keyword1},
{ html: “Archive”,href: “https://archive.org/search.php?query=” + keyword1 },
{ html: “CTEXT古籍”,href: “http://ctext.org/searchbooks.pl?if=gb&searchu=” + keyword1 },
{ html: “哈佛大学”, href: “http://hollis.harvard.edu/primo_library/libweb/action/search.do?mode=Basic&vid=HVD&tab=books&&fn=search&vl(freeText0)=” + keyword1},
{ html: “超星”, href: “http://book.chaoxing.com/search/all/” + keyword1 + “/bookList1_.html”},
{ html: “国学大师”,href: “http://www.guoxuedashi.com/so.php?sokeytm=” + keyword1 },
{ html: “HathiTrust”,href: “https://catalog.hathitrust.org/Search/Home?lookfor=” + keyword1 + “&searchtype=all&ft=&setft=false”},
{ html: “韩国DB”, href: ” http://db.itkc.or.kr/search/group?q=query†” + keyword1},
{ html: “日本国会”,href: “http://dl.ndl.go.jp/search/searchResult?featureCode=all&searchWord=” + keyword1 + “&viewRestricted=0”},
{ html: “美国国会”,href: “https://www.loc.gov/search/?in=&q=” + keyword1 },
英国国会图书馆、学苑汲古、中国国家图书馆等(代码稍长,详见附件)
将以上代码,添加到适当位置即可,当然,你也可以重新排序,也可以自行添加自己想要的网站。实际的效果如图: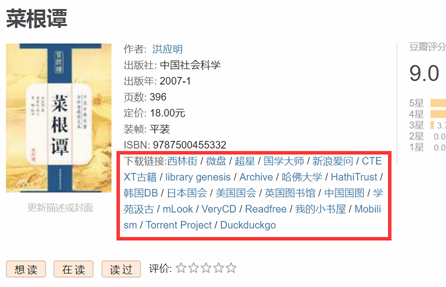
如果你不知道如何添加的话,可以直接下载整个代码文件(百度云盘、OneDrive),完全拷贝过去即可。如果有什么问题,欢迎交流指正。
非常棒的功能!